Kaynaklar
LYK'18 - GNU/Linux Sistem Yönetimi 2. Düzey [Devrim Gündüz]
PostgreSQL Nedir?
PostgreSQL güçlü bir Object-Relational database servisidir.
SQL dilinin kullanıldığı PostgreSQL’in verileri güvenli bir şekilde saklama, karmaşık verileri ölçeklendirme gibi bir çok özelliği vardır.
PostgreSQL tüm ana işletim sistemlerinde çalışır.
PostgreSQL, kanıtlanmış mimarisi, güvenilirliği, veri bütünlüğü, sağlam özellik seti, genişletilebilirliği ve yazılımın arkasındaki açık kaynak topluluğunun sürekli olarak performans ve yenilikçi çözümler sunması ile güçlü bir ün kazanmıştır. [1]
PostgreSQL’in Özellikleri
- Desteklenen database büyüklüğü sonsuzdur.
Bir Tablo’ya en fazla 16 TB veri konabilir ama tablolar alt-tablolara bölünebileceği ve bu alt-tablolar da 16 TB veri saklayabileceği için desteklenen veri büyüklüğü sonsuz olmuş olur.
Desteklenen satır (tuple) sayısı sonsuzdur.
Desteklenen Index sayısı sonsuzdur.
Burada dikkat edilmesi gereken önemli bir husus vardır, eğer index sayısı çok fazla olursa ciddi bir performans kaybı yaşanacaktır.
Object-Relational bir database’dir. (RDMS değil)
Bir tabloda 250-1600 arası kolon (attribute) olabilir.
row = tuple, column = attribute
- PostgreSQL aynı anda 2^32 tane client‘ın bağlanmasını destekler.
4.294.967.296, yani 4 milyar.. Sonsuz diyebiliriz. Tabiki bunu destekleyecek bir altyapı şuan pek mümkün değil.
- Son olarak, PostgreSQL sunucunuz için donanım yükseltmeyi düşünüyorsanız; RAM, RAM alın!
PostgreSQL Nasıl Çalışır?
Bağlantının Kurulması
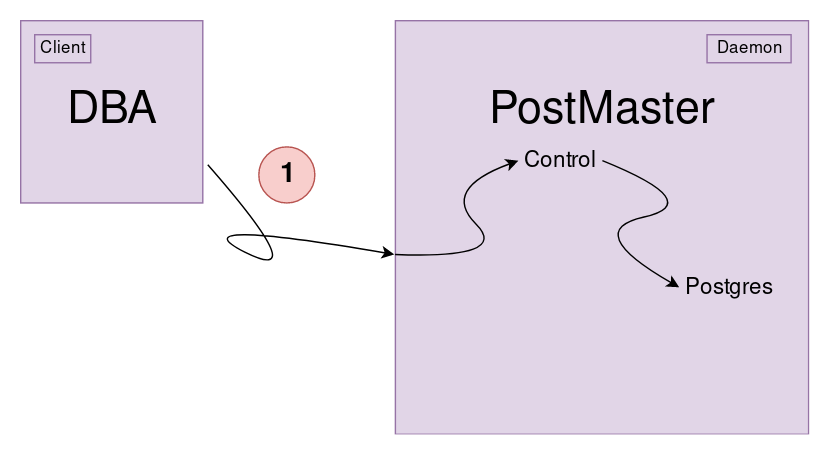
Bir client yani bir DBA PostgreSQL servisine bağlanacağı sırada 3 zorunlu 1 opsiyonel bilgi gereklidir;
- Database Adı
- Kullanıcı Adı
- IP Adresi
- Parola (opsiyonel)
Eğer girilen bilgiler doğru ise Postmaster tarafından bir postgres fork edilir ve client bağlanır. (attach)
Her client bağlandığında ayrı bir postgres fork edilir. Client bağlantısı kesileceğinde bu süreç öldürülür. Öldürme işlemi pg-terminate-backend kullanılır. Kill yerine ayrı bir yapının kullanılmasının sebebi, öldürme işlemlerinin Postmaster’a bildirilmek istenmesidir.
Peki neden thread yerine fork’lama işlemi yapılıyor?. Aslında burada bakış açısı farkı vardır, farklı düşünce şekilleri olabilir. Thread yapısında, her client kapanması durumunda postmaster’ın da kapatılması gerekirdi. Bu yüzden fork’lama tercih edilmiştir.
Genel yapıya bakıldığında her client bağlantısı sağlandığında fork’lama işlemi ve öldürme işleminin yürütüldüğü gözükür. Her bağlantı işleminde bunun yapılması oldukça büyük bir yük yaratacaktır. Bunun engellenmesi amacıyla Connection Pooler kullanılır.
Connection Pooler
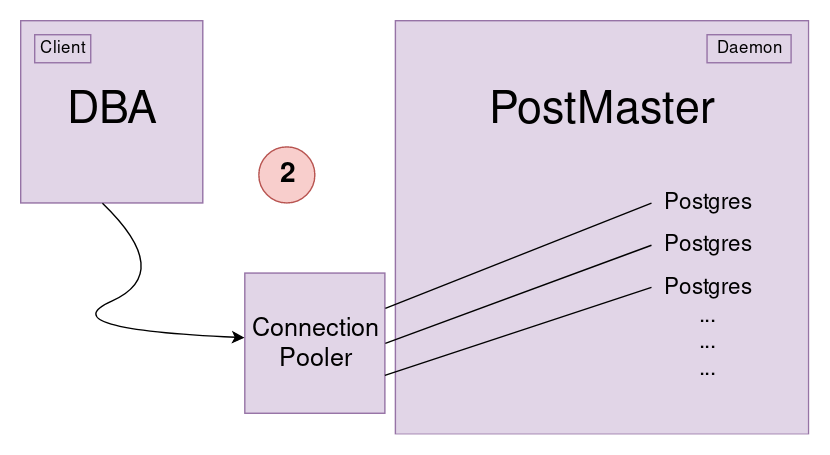
Connection Pooler ile her bağlantı için uygulanan fork’lama işleminin yükü önlenebilir.
Connection Pooler, PostgreSQL başlatıldığında default client sayısı kadar postgres oluşturur ve kendine bağlar.
Postgres’lerin oluşturulması yalnızca 1 kez yapılacağı için pooler sayesinde işlem yükünden ciddi bir kazanç sağlanır.
Bir client bağlanacağında direkt olarak Connection Pooler ile bağlantı kurar. Server ise karşısında direkt olarak Connection Pooler’ı görür.
Connection Pooler ayrı bir sunucuda ya da direkt PostgreSQL ile aynı sunucuda yürütülebilir. Ama aynı sunucuda daha performanslı bir sonuç verecektir.
PostgreSQL default olarak en fazla 100 client kabul edebilir. Bu nedenle default ayarlar ile Connection Pooler çalıştırıldığında kendine 100 tane postgres bağlantısı sağlar. Eğer dışardan gelen client sayısı 100’den fazla olursa, pooler bunları sıraya koyabilir.
PgBouncer bir connection pooler’dır. [2]
Sorguların Çalıştırılması
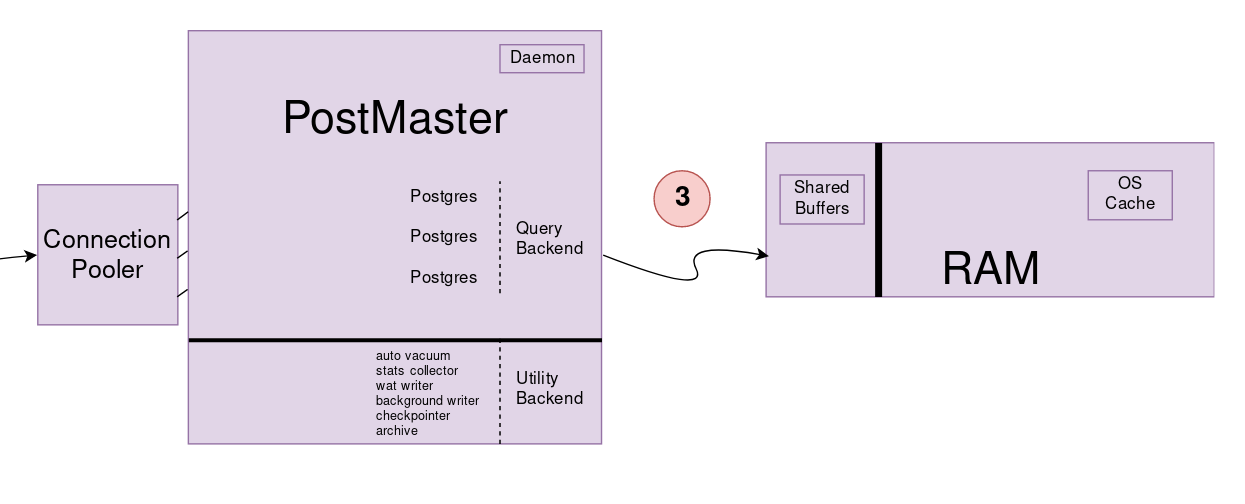
Sorgular için 3 aşama uygulanır.
- Parse
- Analyze (Optimizer)
- Execute
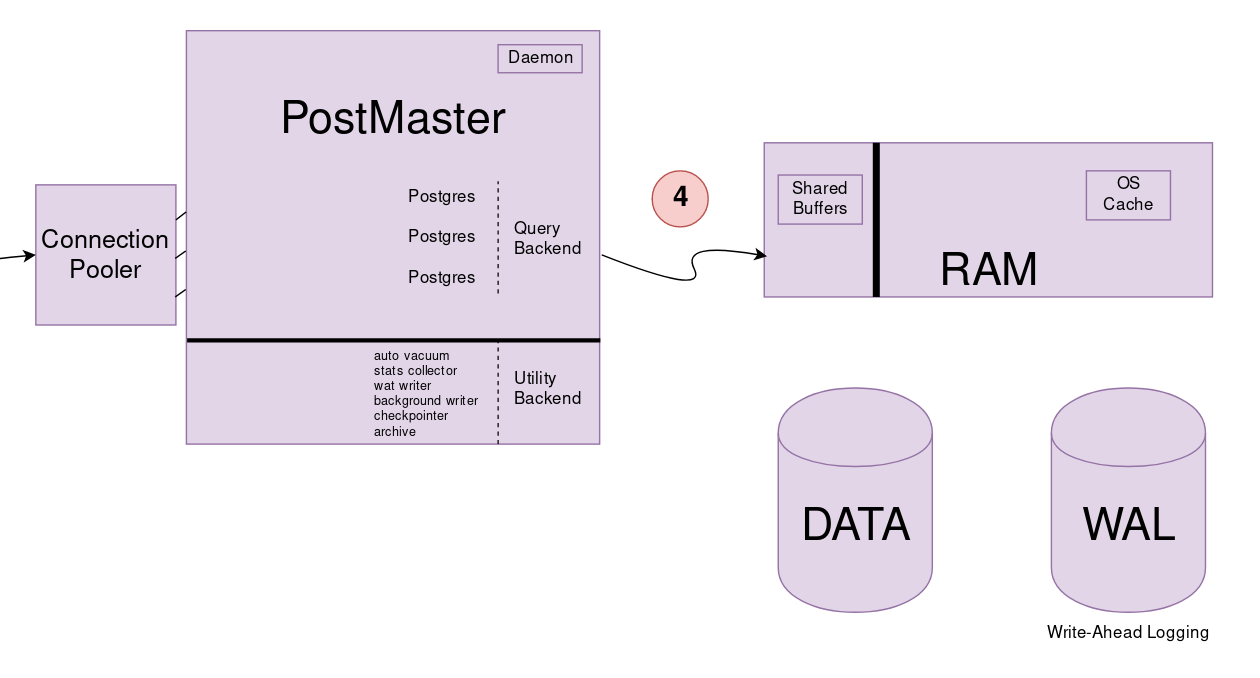
Postgres’e Query Backend denir. Sorgular Postgres tarafından çalıştırılır.
Shared Buffers sabit alanı kernel tarafından ayrılıp postmaster’a verilir. Tüm sorgu (query) işlemleri bu Shared Buffers alanında çalıştırılır. Shared Buffers’ta tutulan veriler veriler diskin bir yansısı olarak düşünülebilir. Diskteki veri ile Shared Buffers’taki veri aynı ise clean buffer olarak adlandırılır. Clean-Dirty durumunu kernel bilir.
SELECT * FROM customers
Bir sorgu çalıştırılacağı zaman Shared Bufffers’da verinin olup olmadığına bakılır, eğer yok ise kernel tarafından ilk olarak cache’e bakılır eğer orada da yok ise diske gidilir, ilgili veriler shared buffers’a taşınır ve sorgu çalıştırılır. Sorgu çalıştırıldıktan sonra sonuç postgres’e atılır, postgres de sonucu client’a yollar.
Eğer yapılan sorgunun sonucunun boyutu shared buffers’ın fiziksel boyutundan büyük ise, shared buffers bypass edilebilir.
INSERT INTO customers(name) VALUES('bora')
Bir insert sorgusu çalıştırılacağı zaman diske yazılmasına gerek yoktur, direkt olarak Shared Buffers’a yazılabilir, daha sonra bu veriler disk ile eşlenir. Disk ile eşlenmemiş, yani disk ile aynı olmayan veriler Dirty Buffer olarak adlandırılır.
Journal Nedir?
Shared Buffers ile Disk arasındaki eşliğin sağlanması için günümüz dosya sistemlerinde kullanılan journal mantığı ile aynı durum söz konusudur.
FAT32’den NTFS’e ve EXT3’den EXT4’e geçildiğinde journal özelliği gelmiştir.
Disklerin default olarak 5%’ i journal olarak tanımlanır. Veriler diske yazılacağında direkt olarak journal bölgesine yazılır, bu bölgeye yazılan veriler belli bir periyod ile dışar flash edilir.
Buradaki mantık küçük bir alana yazma işleminin daha kolay olmasıdır, yazma küçük bir bölgeye yapılır ve bu veriler daha sonra dağıtılır.
PostgreSQL de benzer bir mantık ile çalışır. WAL için postgres’in journal’ı denebilir. [3]
Dirty Buffers
Shared Buffers’taki veriler Clean ve Dirty olmak üzere ikiye ayrılır. Buffer durumu kernel tarafından bilinir. Kernel eğer veriyi götürüyorsa clean, dışarıdan geliyor ise dirty olarak isimlendirir.
Dirty Buffers’ın belli aralıkla ile diske yazılması gerekir. Bunun için Background Writer kullanılır.
Disk üzerinde bir buffer boyutu 8kb iken RAM’de 4kb yer kaplar.
Background Writer belli aralıkla Shared Buffers’taki dirty buffer’ları diske (data) yazar ve flag’lerini değiştirir.
Background Writer default değer olarak 200ms’de 400kb yazacak şekilde ayarlıdır.
Checkpoint, BGW’den farklı olarak, herhangi bir algoritme kullanmadan, direkt olarak tüm dirty buffer’ların DATA’ya yazılmasını sağlar.
Eğer BGW işini düzgün yapamaz ise LRU (Least Recently Used)’ ın başındaki buffer dirty olabilir, böyle olursa LRU gelen sorguyu parse eder ve BGW gibi davranıp, BGW’nin iki katı kadar temizleme yapar. Bu işlem yeteri kadar clean açılasaya kadar devam eder.
BGW Yazma İşlemini Nasıl Yapar?
| r1 | 1 | A |
| r2 | 2 | B |
| r3 | 3 | C |
Örneğin yukardaki gibi bir tablo olsun ve bu tabloda 2. satırı silmek istiyor olalım. Bu durumda ilk aşamada direkt olarak silme işlemi uygulanmaz. 2. satırın visibility’si invisible olarak değiştirilir.
Ya da örneğin 2. satırı silmek yerine güncellemek istiyor olalım, bu durumda ise aynı anda çalışacak şekilde [INSERT + DELETE] işlemleri uygulanır, yani aslında direkt olarak veri değiştirilmez, ilgili veri invisible yapılır ve yani bir satır eklenmiş olur. Update’in bu şekilde yapılması sayesinde farklı tracesection işlemleri yapılabilir.
SELECT cmin,cmax,xmin,xmax FROM table
Silme işleminin bu şekilde geciktirilme sebebi, silmenin oldukça masraflı olmasıdır.
Invisible olarak belirtilen satırlar belli bir periyod ile autovacuum ile temizlenir. Autovacuum ayarlarının düzenlenmesi önemlidir, default ayarlar ile şişme olabilir.
Ayrıca elle de vacuum işlemi yapılabilir.
Örnek Bir PostgreSQL Uygulaması
NOT: Örnek uygulama amacıyla CentOS tercih ettim. Siz başka dağıtımlar tercih edebilirsiniz.
İlk olarak repo adresini eklememiz gerekiyor. [4]
yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm
Ardından PostgreSQL kurulumunu yapalım.
yum install postgresql10-server
Database Class’larını oluşturmak için aşağıdaki komutu yürütüyoruz.
/usr/pgsql-10/bin/postgresql-10-setup initdb
Herşey hazır, servisi başlatabiliriz.
systemctl start postgresql-10.service
Sistemimizde otomatik olarak postgres isimli bir kullanıcı oluşturuldu.
grep "postgres" /etc/passwd
Bu kullanıcıya geçiş yapalım. Bu aşamada parola sorgusunu atlatmak için komutu root yetkisi ile çalıştırmalısınız. Parola belirlemek istiyorsanız (sudo passwd postgres diyebilirsiniz.)
su - postgres
Ardından aşağıdaki komut ile sisteme girilir.
psql
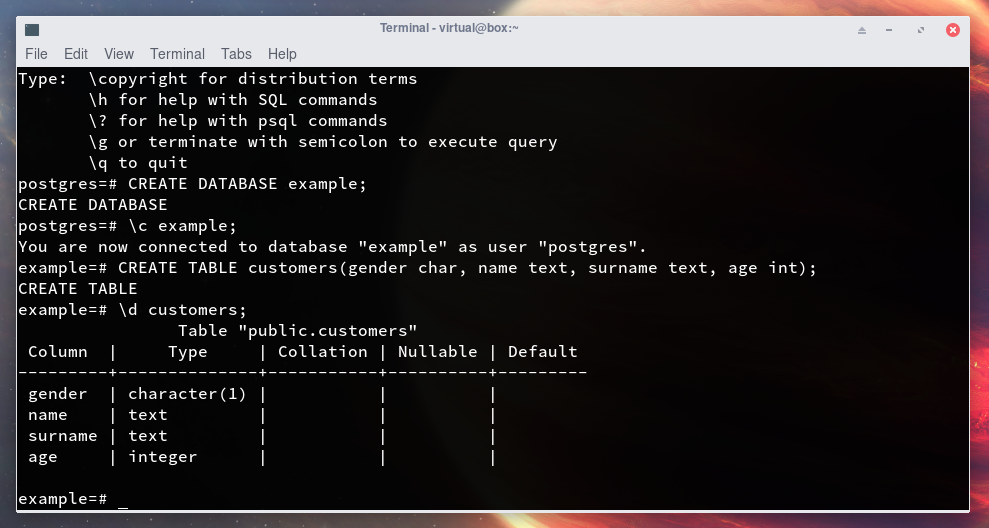
Şimdi örnek için kullanacağımız Database’i oluşturalım.
CREATE DATABASE example;
İşlemleri belli bir database üzerinde yapmak için connect olmamız gerekmekte. Aşağıdaki gibi oluşturduğumuz database’e connect olalım.
\c example;
Şimdi örnek bir tablo oluşturalım.
CREATE TABLE customers(gender char, name text, surname text, age int);
Oluşan tabloları görüntülemek için \d kullanılır. Aşağıdaki gibi oluşturduğumuz tabloyu görüntüleyebiliriz.
\d customers;
Aşağıdaki gibi yeni bir müşteri eklemesi yapabiliriz.
INSERT INTO customers VALUES('M', 'Bora', 'Tanrikulu', 21);
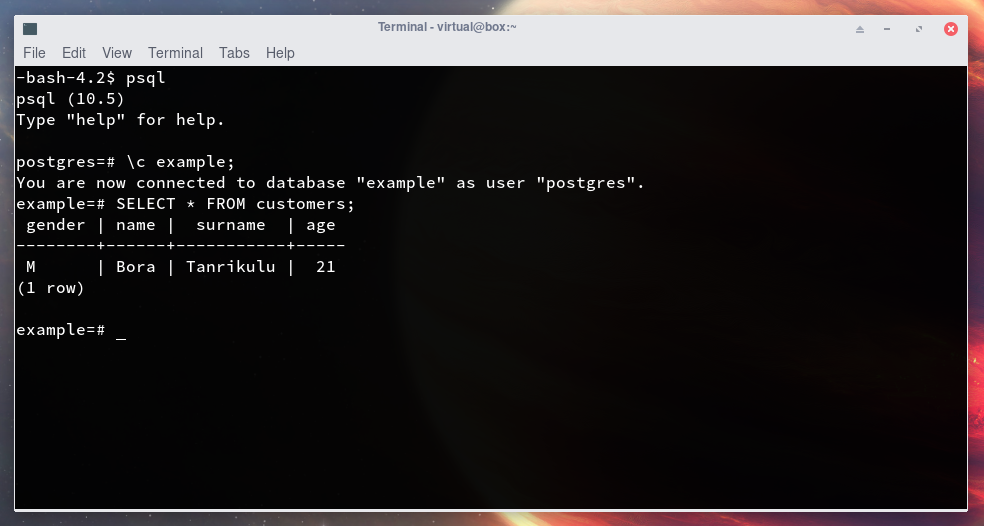
Son olarak yaptığımız işlemin sonucu görmek için tüm tabloyu görüntüleyelim.
SELECT * FROM customers;